



Robert Khasanov |
||
 |
Phone Fax Visitor's Address |
+49 (0)351 463 39978 +49 (0)351 463 39995 Helmholtzstrasse 18 |
Robert Khasanov has received his Bachelor's and Master’s degree in Computer Science from Moscow Institute of Physics and Technology in 2012 and 2014 respectively. During the study, he also held positions at Intel where he was working on optimising binary translator system, and then in LLVM compiler project. In 2015 Robert carried out an internship at Scalable Parallel Computing Lab (ETH Zurich) where he was working on optimal data replication in fault tolerant distributed databases. Currently, Robert is a Ph.D. student at the Chair for Compiler Construction. In his studies, he works on language support and optimizations for energy-efficient execution of multiple applications on emerging systems. Key interests include dataflow languages with implicit and explicit parallelism, compiler-runtime interaction, and energy optimizations.
At the Chair for Compiler Construction, we are developing a hybrid system called TETRiS, which aims at energy-efficient and predictable execution of multiple applications. The system exploits inherited symmetries in hardware and software to reduce the design space exploration. The approach consists of two parts, at design-time, the set of Pareto-optimal configurations is generated, and then depending on the current workload, the configurations are selected and transformed at runtime.
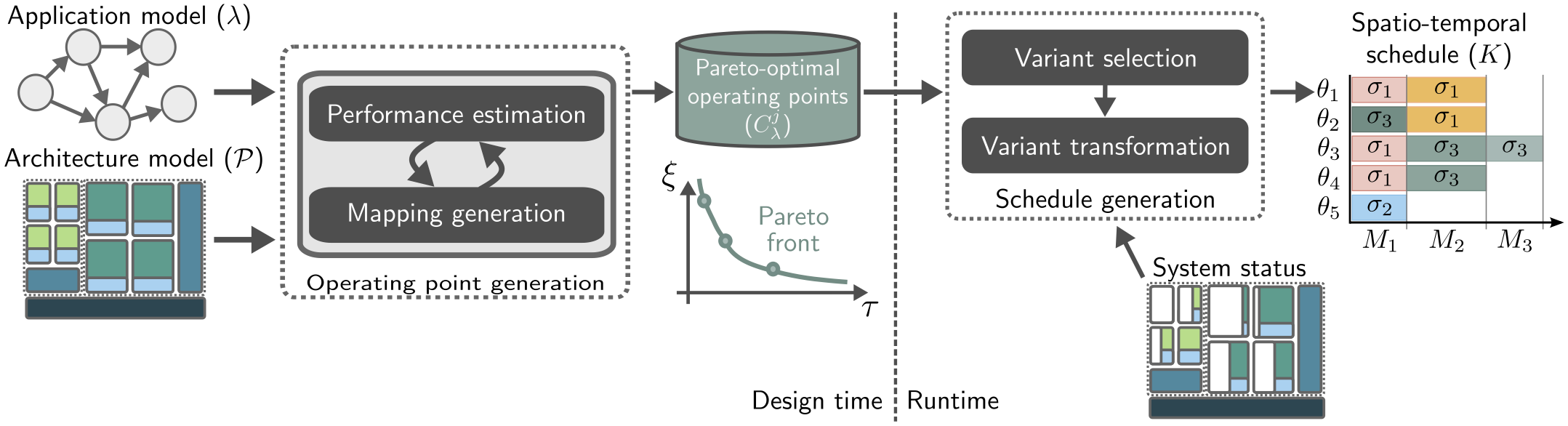
Possible project topics include:
- Runtime adaptivity of Kahn Process Networks with implicit parallelism
Kahn process networks (KPN) are an abstraction for modeling computation which makes communication patterns explicit. An extension of implicit parallelism for KPN allows applications to change the number of used resources at runtime in a malleable way, which allows applications to adapt to the changes in the environment and, therefore, achieve better energy efficiency. In this project, you will develop this application model in the Mocasin framework, extending the hybrid methodology for this class of applications.
- Frequency scaling in hybrid mapping methodology
Dynamic Voltage Frequency Scaling (DVFS) allows reducing the energy consumption of the system further. A naive approach to adapt DVFS in the hybrid methodology would be to generate the operating points for each available frequency configuration of the platform. This, however, would lead to a blow-up of operating points and a complex runtime algorithm. In this research project, you will develop an interplay of the hybrid methodology with frequency scaling.
- A hybrid approach for mixed-critical applications
In this work, you will refine the hybrid methodology approach for non-real-time application and mixed-criticality applications.
- Runtime scheduling in Linux
In this work, you will develop the runtime algorithm in the prototype in C++ for scheduling applications running on Linux.
This list is open-ended. Feel free to approach me and discuss these or other ideas.
If you are interested, please contact me by email.
2024
- Robert Khasanov, Marc Dietrich, Jeronimo Castrillon, "Flexible Spatio-Temporal Energy-Efficient Runtime Management", In Proceeding: 29th Asia and South Pacific Design Automation Conference (ASP-DAC’24), pp. 777–784, Jan 2024. [doi] [Bibtex & Downloads]
Flexible Spatio-Temporal Energy-Efficient Runtime Management
×Reference
Robert Khasanov, Marc Dietrich, Jeronimo Castrillon, "Flexible Spatio-Temporal Energy-Efficient Runtime Management", In Proceeding: 29th Asia and South Pacific Design Automation Conference (ASP-DAC’24), pp. 777–784, Jan 2024. [doi]
Bibtex
@InProceedings{khasanov_aspdac24,
author = {Robert Khasanov and Marc Dietrich and Jeronimo Castrillon},
booktitle = {29th Asia and South Pacific Design Automation Conference (ASP-DAC’24)},
title = {Flexible Spatio-Temporal Energy-Efficient Runtime Management},
location = {Incheon, South Korea},
organization = {IEEE},
pages = {777--784},
month = jan,
year = {2024},
url = {https://ieeexplore.ieee.org/document/10473885},
doi = {10.1109/ASP-DAC58780.2024.10473885},
}Downloads
2401_Khasanov_ASPDAC [PDF]
Permalink
2023
- Till Smejkal, Robert Khasanov, Jeronimo Castrillon, Hermann Härtig, "Management of Energy-Aware Processes in Heterogeneous Architectures", In Poster at the 29th ACM Symposium on Operating Systems Principles (SOSP’23 Posters), Oct 2023. [Bibtex & Downloads]
Management of Energy-Aware Processes in Heterogeneous Architectures
×Reference
Till Smejkal, Robert Khasanov, Jeronimo Castrillon, Hermann Härtig, "Management of Energy-Aware Processes in Heterogeneous Architectures", In Poster at the 29th ACM Symposium on Operating Systems Principles (SOSP’23 Posters), Oct 2023.
Bibtex
@Misc{smejkal_poster-sosp23,
author = {Till Smejkal and Robert Khasanov and Jeronimo Castrillon and Hermann H{\"a}rtig},
title = {Management of Energy-Aware Processes in Heterogeneous Architectures},
howpublished = {Poster at the 29th ACM Symposium on Operating Systems Principles (SOSP’23 Posters)},
location = {Koblenz, Germany},
month = oct,
year = {2023},
}Downloads
No Downloads available for this publication
Permalink
2021
- Robert Khasanov, Julian Robledo, Christian Menard, Andr'es Goens, Jeronimo Castrillon, "Domain-specific hybrid mapping for energy-efficient baseband processing in wireless networks", In ACM Transactions on Embedded Computing Systems (TECS). Special issue of the International Conference on Compilers, Architecture, and Synthesis of Embedded Systems (CASES), Association for Computing Machinery, vol. 20, no. 5s, New York, NY, USA, Sep 2021. [doi] [Bibtex & Downloads]
Domain-specific hybrid mapping for energy-efficient baseband processing in wireless networks
×Reference
Robert Khasanov, Julian Robledo, Christian Menard, Andr'es Goens, Jeronimo Castrillon, "Domain-specific hybrid mapping for energy-efficient baseband processing in wireless networks", In ACM Transactions on Embedded Computing Systems (TECS). Special issue of the International Conference on Compilers, Architecture, and Synthesis of Embedded Systems (CASES), Association for Computing Machinery, vol. 20, no. 5s, New York, NY, USA, Sep 2021. [doi]
Abstract
Advancing telecommunication standards continuously push for larger bandwidths, lower latencies, and faster data rates. The receiver baseband unit not only has to deal with a huge number of users expecting connectivity but also with a high workload heterogeneity. As a consequence of the required flexibility, baseband processing has seen a trend towards software implementations in cloud Radio Access Networks (cRANs). The flexibility gained from software implementation comes at the price of impoverished energy efficiency. This paper addresses the trade-off between flexibility and efficiency by proposing a domain-specific hybrid mapping algorithm. Hybrid mapping is an established approach from the model-based design of embedded systems that allows us to retain flexibility while targeting heterogeneous hardware. Depending on the current workload, the runtime system selects the most energy-efficient mapping configuration without violating timing constraints. We leverage the structure of baseband processing, and refine the scheduling methodology, to enable efficient mapping of 100s of tasks at the millisecond granularity, improving upon state-of-the-art hybrid approaches. We validate our approach on an Odroid XU4 and virtual platforms with application-specific accelerators on an open-source prototype. On different LTE workloads, our hybrid approach shows significant improvements both at design time and at runtime. At design-time, mappings of similar quality to those obtained by state-of-the-art methods are generated around four orders of magnitude faster. At runtime, multi-application schedules are computed 37.7% faster than the state-of-the-art without compromising on the quality.
Bibtex
@Article{khasanov_cases21,
author = {Robert Khasanov and Julian Robledo and Christian Menard and Andrés Goens and Jeronimo Castrillon},
title = {Domain-specific hybrid mapping for energy-efficient baseband processing in wireless networks},
doi = {10.1145/3476991},
issn = {1539-9087},
number = {5s},
url = {https://doi.org/10.1145/3476991},
volume = {20},
abstract = {Advancing telecommunication standards continuously push for larger bandwidths, lower latencies, and faster data rates. The receiver baseband unit not only has to deal with a huge number of users expecting connectivity but also with a high workload heterogeneity. As a consequence of the required flexibility, baseband processing has seen a trend towards software implementations in cloud Radio Access Networks (cRANs). The flexibility gained from software implementation comes at the price of impoverished energy efficiency. This paper addresses the trade-off between flexibility and efficiency by proposing a domain-specific hybrid mapping algorithm. Hybrid mapping is an established approach from the model-based design of embedded systems that allows us to retain flexibility while targeting heterogeneous hardware. Depending on the current workload, the runtime system selects the most energy-efficient mapping configuration without violating timing constraints. We leverage the structure of baseband processing, and refine the scheduling methodology, to enable efficient mapping of 100s of tasks at the millisecond granularity, improving upon state-of-the-art hybrid approaches. We validate our approach on an Odroid XU4 and virtual platforms with application-specific accelerators on an open-source prototype. On different LTE workloads, our hybrid approach shows significant improvements both at design time and at runtime. At design-time, mappings of similar quality to those obtained by state-of-the-art methods are generated around four orders of magnitude faster. At runtime, multi-application schedules are computed 37.7% faster than the state-of-the-art without compromising on the quality.},
address = {New York, NY, USA},
articleno = {60},
issue_date = {October 2021},
journal = {ACM Transactions on Embedded Computing Systems (TECS). Special issue of the International Conference on Compilers, Architecture, and Synthesis of Embedded Systems (CASES)},
location = {Virtual conference},
month = sep,
numpages = {26},
publisher = {Association for Computing Machinery},
year = {2021},
}Downloads
2110_Khasanov_CASES [PDF]
Related Paths
Permalink
- Christian Menard, Andr'es Goens, Gerald Hempel, Robert Khasanov, Julian Robledo, Felix Teweleitt, Jeronimo Castrillon, "Mocasin—Rapid Prototyping of Rapid Prototyping Tools: A Framework for Exploring New Approaches in Mapping Software to Heterogeneous Multi-cores", Proceedings of the 2021 Drone Systems Engineering and Rapid Simulation and Performance Evaluation: Methods and Tools, co-located with 16th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC), Association for Computing Machinery, pp. 66–73, New York, NY, USA, Jan 2021. (Video Presentation) [doi] [Bibtex & Downloads]
Mocasin—Rapid Prototyping of Rapid Prototyping Tools: A Framework for Exploring New Approaches in Mapping Software to Heterogeneous Multi-cores
×Reference
Christian Menard, Andr'es Goens, Gerald Hempel, Robert Khasanov, Julian Robledo, Felix Teweleitt, Jeronimo Castrillon, "Mocasin—Rapid Prototyping of Rapid Prototyping Tools: A Framework for Exploring New Approaches in Mapping Software to Heterogeneous Multi-cores", Proceedings of the 2021 Drone Systems Engineering and Rapid Simulation and Performance Evaluation: Methods and Tools, co-located with 16th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC), Association for Computing Machinery, pp. 66–73, New York, NY, USA, Jan 2021. (Video Presentation) [doi]
Abstract
We present Mocasin, an open-source rapid prototyping framework for researching, implementing and validating new algorithms and solutions in the field of mapping software to heterogeneous multi-cores. In contrast to the many existing tools that often specialize for a particular use-case, Mocasin is an open, flexible and generic research environment that abstracts over the approaches taken by other tools. Mocasin is designed to support a wide range of models of computation and input formats, implements manifold mapping strategies and provides an adjustable high-level simulator for performance estimation. This infrastructure serves as a flexible vehicle for exploring new approaches and as a blueprint for building customized tools. We highlight the key design aspects of Mocasin that enable its flexibility and illustrate its capabilities in a case-study showing how Mocasin can be used for building a customized tool for researching runtime mapping strategies in an LTE uplink receiver.
Bibtex
@InProceedings{menard_rapido21,
author = {Christian Menard and Andrés Goens and Gerald Hempel and Robert Khasanov and Julian Robledo and Felix Teweleitt and Jeronimo Castrillon},
title = {Mocasin---Rapid Prototyping of Rapid Prototyping Tools: A Framework for Exploring New Approaches in Mapping Software to Heterogeneous Multi-cores},
booktitle = {Proceedings of the 2021 Drone Systems Engineering and Rapid Simulation and Performance Evaluation: Methods and Tools, co-located with 16th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC)},
year = {2021},
address = {New York, NY, USA},
month = jan,
publisher = {ACM},
doi = {10.1145/3444950.3447285},
isbn = {9781450389525},
location = {Budapest, Hungary},
pages = {66–73},
publisher = {Association for Computing Machinery},
series = {DroneSE and RAPIDO '21},
url = {https://doi.org/10.1145/3444950.3447285},
abstract = {We present Mocasin, an open-source rapid prototyping framework for researching, implementing and validating new algorithms and solutions in the field of mapping software to heterogeneous multi-cores. In contrast to the many existing tools that often specialize for a particular use-case, Mocasin is an open, flexible and generic research environment that abstracts over the approaches taken by other tools. Mocasin is designed to support a wide range of models of computation and input formats, implements manifold mapping strategies and provides an adjustable high-level simulator for performance estimation. This infrastructure serves as a flexible vehicle for exploring new approaches and as a blueprint for building customized tools. We highlight the key design aspects of Mocasin that enable its flexibility and illustrate its capabilities in a case-study showing how Mocasin can be used for building a customized tool for researching runtime mapping strategies in an LTE uplink receiver.},
numpages = {8},
}Downloads
2101_Menard_RAPIDO [PDF]
Permalink
2020
- Robert Khasanov, Jeronimo Castrillon, "Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping", Proceedings of the 2020 Design, Automation and Test in Europe Conference (DATE), IEEE, pp. 909–914, Mar 2020. (Best paper award candidate E-Track, Video Presentation) [doi] [Bibtex & Downloads]
Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping
×Reference
Robert Khasanov, Jeronimo Castrillon, "Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping", Proceedings of the 2020 Design, Automation and Test in Europe Conference (DATE), IEEE, pp. 909–914, Mar 2020. (Best paper award candidate E-Track, Video Presentation) [doi]
Abstract
Modern embedded computing platforms consist of a high amount of heterogeneous resources, which allows executing multiple applications on a single device. The number of running application on the system varies with time and so does the amount of available resources. This has considerably increased the complexity of analysis and optimization algorithms for runtime mapping of firm real-time applications. To reduce the runtime overhead, researchers have proposed to pre-compute partial mappings at compile time and have the runtime efficiently compute the final mapping. However, most existing solutions only compute a fixed mapping for a given set of running applications, and the mapping is defined for the entire duration of the workload execution. In this work we allow applications to adapt to the amount of available resources by using mapping segments. This way, applications may switch between different configurations with varied degree of parallelism. We present a runtime manager for firm real-time applications that generates such mapping segments based on partial solutions and aims at minimizing the overall energy consumption without deadline violations. The proposed algorithm outperforms the state-of-the-art approaches on the overall energy consumption by up to 13% while incurring an order of magnitude less scheduling overhead.
Bibtex
@InProceedings{khasanov_date20,
author = {Robert Khasanov and Jeronimo Castrillon},
title = {Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping},
booktitle = {Proceedings of the 2020 Design, Automation and Test in Europe Conference (DATE)},
year = {2020},
series = {DATE '20},
month = mar,
publisher = {IEEE},
location = {Grenoble, France},
isbn = {978-3-9819263-4-7},
pages = {909--914},
doi = {10.23919/DATE48585.2020.9116381},
url = {https://ieeexplore.ieee.org/document/9116381},
abstract = {Modern embedded computing platforms consist of a high amount of heterogeneous resources, which allows executing multiple applications on a single device. The number of running application on the system varies with time and so does the amount of available resources. This has considerably increased the complexity of analysis and optimization algorithms for runtime mapping of firm real-time applications. To reduce the runtime overhead, researchers have proposed to pre-compute partial mappings at compile time and have the runtime efficiently compute the final mapping. However, most existing solutions only compute a fixed mapping for a given set of running applications, and the mapping is defined for the entire duration of the workload execution. In this work we allow applications to adapt to the amount of available resources by using mapping segments. This way, applications may switch between different configurations with varied degree of parallelism. We present a runtime manager for firm real-time applications that generates such mapping segments based on partial solutions and aims at minimizing the overall energy consumption without deadline violations. The proposed algorithm outperforms the state-of-the-art approaches on the overall energy consumption by up to 13% while incurring an order of magnitude less scheduling overhead.},
}Downloads
2003_Khasanov_DATE [PDF]
Related Paths
Permalink
2018
- Robert Khasanov, Andrés Goens, Jeronimo Castrillon, "Implicit Data-Parallelism in Kahn Process Networks: Bridging the MacQueen Gap", Proceedings of the 9th Workshop and 7th Workshop on Parallel Programming and RunTime Management Techniques for Manycore Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'18), co-located with 13th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC), ACM, pp. 20–25, New York, NY, USA, Jan 2018. [doi] [Bibtex & Downloads]
Implicit Data-Parallelism in Kahn Process Networks: Bridging the MacQueen Gap
×Reference
Robert Khasanov, Andrés Goens, Jeronimo Castrillon, "Implicit Data-Parallelism in Kahn Process Networks: Bridging the MacQueen Gap", Proceedings of the 9th Workshop and 7th Workshop on Parallel Programming and RunTime Management Techniques for Manycore Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'18), co-located with 13th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC), ACM, pp. 20–25, New York, NY, USA, Jan 2018. [doi]
Abstract
Modern embedded systems are rapidly increasing their complexity, both in terms of numbers of cores, as well as heterogeneity. To generate efficient code for these systems, it is common to leverage formal models of computation.
Among these, the dataflow model of Kahn Process Networks (KPN) is widespread because it is expressive but guarantees a deterministic execution. However, the KPN model is ill-suited to expose data-level parallelism, since this has to be made explicit in the process network. This is aggravated by the fact that its most common execution model, Kahn-MacQueen, poses restrictive conditions on the scheduling of data-parallel processes, leading to an inefficient execution. In this paper we present a novel extension to the KPN model and a relaxed execution strategy that addresses this problem, while keeping the deterministic KPN semantics. It improves run-time adaptivity in malleable way and provides implicit parallelism. We evaluate our approach on two architectures, improving the performance of a benchmark by up to 25.6% on an Intel chip with hyper-threading, and by up to 78.0% on a heterogeneous embedded ARM big.LITTLE architecture.Bibtex
@InProceedings{khasanov_parma18,
author = {Robert Khasanov and Andr\'{e}s Goens and Jeronimo Castrillon},
title = {Implicit Data-Parallelism in Kahn Process Networks: Bridging the MacQueen Gap},
booktitle = {Proceedings of the 9th Workshop and 7th Workshop on Parallel Programming and RunTime Management Techniques for Manycore Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'18), co-located with 13th International Conference on High-Performance and Embedded Architectures and Compilers (HiPEAC)},
series = {PARMA-DITAM '18},
isbn = {978-1-4503-6444-7},
pages = {20--25},
year = {2018},
month = jan,
numpages = {6},
url = {http://doi.acm.org/10.1145/3183767.3183790},
doi = {10.1145/3183767.3183790},
acmid = {3183790},
publisher = {ACM},
address = {New York, NY, USA},
location = {Manchester, United Kingdom},
abstract = {Modern embedded systems are rapidly increasing their complexity, both in terms of numbers of cores, as well as heterogeneity. To generate efficient code for these systems, it is common to leverage formal models of computation.
Among these, the dataflow model of Kahn Process Networks (KPN) is widespread because it is expressive but guarantees a deterministic execution. However, the KPN model is ill-suited to expose data-level parallelism, since this has to be made explicit in the process network. This is aggravated by the fact that its most common execution model, Kahn-MacQueen, poses restrictive conditions on the scheduling of data-parallel processes, leading to an inefficient execution. In this paper we present a novel extension to the KPN model and a relaxed execution strategy that addresses this problem, while keeping the deterministic KPN semantics. It improves run-time adaptivity in malleable way and provides implicit parallelism. We evaluate our approach on two architectures, improving the performance of a benchmark by up to 25.6% on an Intel chip with hyper-threading, and by up to 78.0% on a heterogeneous embedded ARM big.LITTLE architecture.},
}Downloads
1801_Khasanov_PARMA-DITAM [PDF]
Related Paths
Permalink
2017
- Andrés Goens, Robert Khasanov, Marcus Hähnel, Till Smejkal, Hermann Härtig, Jeronimo Castrillon, "TETRiS: a Multi-Application Run-Time System for Predictable Execution of Static Mappings", Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems (SCOPES'17), ACM, pp. 11–20, New York, NY, USA, Jun 2017. [doi] [Bibtex & Downloads]
TETRiS: a Multi-Application Run-Time System for Predictable Execution of Static Mappings
×Reference
Andrés Goens, Robert Khasanov, Marcus Hähnel, Till Smejkal, Hermann Härtig, Jeronimo Castrillon, "TETRiS: a Multi-Application Run-Time System for Predictable Execution of Static Mappings", Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems (SCOPES'17), ACM, pp. 11–20, New York, NY, USA, Jun 2017. [doi]
Bibtex
@InProceedings{goens_scopes17,
author = {Andr\'{e}s Goens and Robert Khasanov and Marcus H{\"a}hnel and Till Smejkal and Hermann H{\"a}rtig and Jeronimo Castrillon},
title = {TETRiS: a Multi-Application Run-Time System for Predictable Execution of Static Mappings},
booktitle = {Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems (SCOPES'17)},
year = {2017},
month = jun,
series = {SCOPES '17},
isbn = {978-1-4503-5039-6},
location = {Sankt Goar, Germany},
pages = {11--20},
numpages = {10},
url = {http://doi.acm.org/10.1145/3078659.3078663},
doi = {10.1145/3078659.3078663},
acmid = {3078663},
publisher = {ACM},
address = {New York, NY, USA}
}Downloads
1706_Goens_SCOPES [PDF]
Related Paths
Permalink
- Markus Haehnel, Frehiwot Melak Arega, Waltenegus Dargie, Robert Khasanov, Jeronimo Castrillon, "Application Interference Analysis: Towards Energy-efficient Workload Management on Heterogeneous Micro-Server Architectures", Proceedings of the 7th International Workshop on Big Data in Cloud Performance (DCPerf'17), IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), pp. 432-437, May 2017. [doi] [Bibtex & Downloads]
Application Interference Analysis: Towards Energy-efficient Workload Management on Heterogeneous Micro-Server Architectures
×Reference
Markus Haehnel, Frehiwot Melak Arega, Waltenegus Dargie, Robert Khasanov, Jeronimo Castrillon, "Application Interference Analysis: Towards Energy-efficient Workload Management on Heterogeneous Micro-Server Architectures", Proceedings of the 7th International Workshop on Big Data in Cloud Performance (DCPerf'17), IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), pp. 432-437, May 2017. [doi]
Bibtex
@InProceedings{khasanov_dcperf17,
author = {Markus Haehnel and Frehiwot Melak Arega and Waltenegus Dargie and Robert Khasanov and Jeronimo Castrillon},
title = {Application Interference Analysis: Towards Energy-efficient Workload Management on Heterogeneous Micro-Server Architectures},
booktitle = {Proceedings of the 7th International Workshop on Big Data in Cloud Performance (DCPerf'17), IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS)},
year = {2017},
month = may,
volume={},
number={},
pages={432-437},
doi={10.1109/INFCOMW.2017.8116415},
ISSN={},
url = {http://ieeexplore.ieee.org/document/8116415/},
location = {Atlanta, USA}
}Downloads
1705_Khasanov_DCPerf [PDF]
Related Paths
Permalink
2016
- Andres Goens, Robert Khasanov, Jeronimo Castrillon, Simon Polstra, Andy Pimentel, "Why Comparing System-level MPSoC Mapping Approaches is Difficult: a Case Study", Proceedings of the IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC-16), pp. 281-288, Ecole Centrale de Lyon, Lyon, France, Sep 2016. [doi] [Bibtex & Downloads]
Why Comparing System-level MPSoC Mapping Approaches is Difficult: a Case Study
×Reference
Andres Goens, Robert Khasanov, Jeronimo Castrillon, Simon Polstra, Andy Pimentel, "Why Comparing System-level MPSoC Mapping Approaches is Difficult: a Case Study", Proceedings of the IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC-16), pp. 281-288, Ecole Centrale de Lyon, Lyon, France, Sep 2016. [doi]
Abstract
Software abstractions are crucial to effectively program heterogeneous Multi-Processor Systems on Chip (MPSoCs). Prime examples of such abstractions are Kahn Process Networks (KPNs) and execution traces. When modeling computation as a KPN, one of the key challenges is to obtain a good mapping, i.e., an assignment of logical computation and communication to physical resources. In this paper we compare two system-level frameworks for solving the mapping problem: Sesame and MAPS. These frameworks, while superficially similar, embody different approaches. Sesame, motivated by modeling and design-space exploration, uses evolutionary algorithms for mapping. MAPS, being a compiler framework, uses simple and fast heuristics instead. In this work we highlight the value of common abstractions, such as KPNs and traces, as a vehicle to enable comparisons between large independent frameworks. These types of comparisons are fundamental for advancing research in the area. At the same time, we illustrate how the lack of formalized models at the hardware level are an obstacle to achieving fair comparisons. Additionally, using a set of applications from the embedded systems domain, we observe that genetic algorithms tend to outperform heuristics by a factor between 1x and 5x, with notable exceptions. This performance comes at the cost of a longer computation time, between 0 and 2 orders of magnitude in our experiments.
Bibtex
@InProceedings{goen_mcsoc16,
author= {Andres Goens and Robert Khasanov and Jeronimo Castrillon and Simon Polstra and Andy Pimentel},
title= {Why Comparing System-level {MPSoC} Mapping Approaches is Difficult: a Case Study},
booktitle= {Proceedings of the IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC-16)},
year= {2016},
address= {Ecole Centrale de Lyon, Lyon, France},
month= sep,
pages = {281-288},
doi = {10.1109/MCSoC.2016.48},
abstract = {Software abstractions are crucial to effectively program heterogeneous Multi-Processor Systems on Chip (MPSoCs). Prime examples of such abstractions are Kahn Process Networks (KPNs) and execution traces. When modeling computation as a KPN, one of the key challenges is to obtain a good mapping, i.e., an assignment of logical computation and communication to physical resources. In this paper we compare two system-level frameworks for solving the mapping problem: Sesame and MAPS. These frameworks, while superficially similar, embody different approaches. Sesame, motivated by modeling and design-space exploration, uses evolutionary algorithms for mapping. MAPS, being a compiler framework, uses simple and fast heuristics instead. In this work we highlight the value of common abstractions, such as KPNs and traces, as a vehicle to enable comparisons between large independent frameworks. These types of comparisons are fundamental for advancing research in the area. At the same time, we illustrate how the lack of formalized models at the hardware level are an obstacle to achieving fair comparisons. Additionally, using a set of applications from the embedded systems domain, we observe that genetic algorithms tend to outperform heuristics by a factor between 1x and 5x, with notable exceptions. This performance comes at the cost of a longer computation time, between 0 and 2 orders of magnitude in our experiments.},
days= {21},
url = {https://cfaed.tu-dresden.de/files/user/jcastrillon/publications/1609_Goens_MCSoC.pdf}
}Downloads
1609_Goens_MCSoC [PDF]
Related Paths
Permalink